In contrast to Classification problems, where there is a finite number of labels for the dependent variable, and in Regression Problems, unlike Classification problems, where there are only a few labels in the Regression Problem, the dependent variable has constant values, i.e., numbers. The goal of predicting is to find values that match as closely to the labeling of the original continuous values as it is possible (without creating a model that will overfit).
The algorithm learning learns an algorithm by studying data from the variables that are independent, as well as their labels that correspond to the dependent variable. The algorithm then utilizes the algorithm to predict the results of dependent variables based on a particular data set from that independent variable.
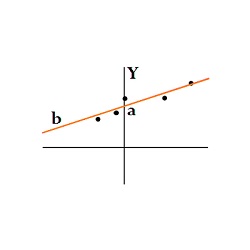
A typical illustration of a Regression Problem could be “House Price,” in which the independent variables include ‘Size of the house,’ the ‘Number of rooms’ as well as ‘Neighbourhood’ while the dependent variable, ‘Price of House’ needs to be Predict.
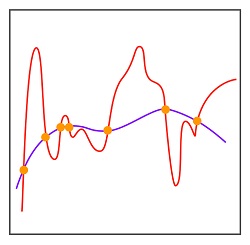
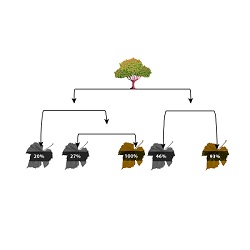
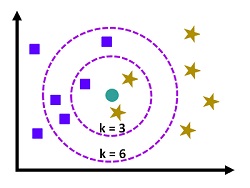
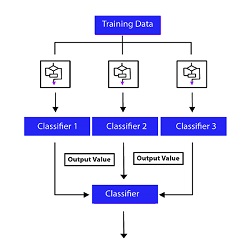
To address this issue, there are a variety of learning algorithms that can be utilized in the Supervised Learning Environment. This includes Liner Regression in which relationships between dependent and independent variables are deemed to be Linear. Additionally, Regularised Linear Regression can be employed to manage overfitting. Decision Trees are also possible alongside other methods, like KNN, which is an instance-based method. Many ensemble methods can be employed that employ various algorithms to produce an output.
Machine Learning Algorithms used only for Regression Problem