
Important Methods of FEATURE REDUCTION
The amount of data generated in recent years has increased exponentially, resulting in more advanced models and greater accuracy.
The sheer volume of data one receives can often be overwhelming. There are many features, making it difficult to do data exploration. High data volumes have their own drawbacks. They can increase the computational time, reduce storage, and, most importantly, cause multicollinearity, which causes models to overfit. These issues have led to various dimensionality reduction methods being developed. Data mining algorithms are feature-based, so it is important to reduce the number of features in the dataset.
Feature Reduction, also known as Dimensionality Reduction, is a technique that reduces the time it takes to process complex algorithms. A low number of features also means that you have more storage space. These benefits are hardware-related. However, Feature Reduction’s greatest benefit is its ability to solve the multicollinearity problem.
Feature Reduction makes data analysis more efficient and accurate.
Feature Selection or Feature Extraction are two types of feature reduction techniques.
Feature Selection is a process that determines the value of a feature using various techniques. Once the less-useful features are identified, they are removed from the dataset. This is also the main difference between Feature Selection and the next type of Feature Reduction- Feature Extract.
Principal Component Analysis is the most popular method for Feature Extraction. This involves reducing the data from high-dimensional space to lower dimensions. Simply put, our features are transformed into lower numbers of artificial features without losing much information.
The prime difference between both methods is that feature selection takes into account the target variable, and the methods work in a supervised environment. Eventually, features are dropped to reduce their number, creating a new set. However, feature extraction is different because we don’t discard any features and don’t create a whole set of new features. Instead, we extract the variance from all features and create an artificial set with most of the variance in the original set.
You can also use classification methods. Factor Analysis is one of the most popular classification methods used for feature reduction. The features are grouped based on their similarity, determined by their shared variance. The user then can choose relevant features from these groups to make the feature set unique.
These methods and more are discussed in the blogs below.
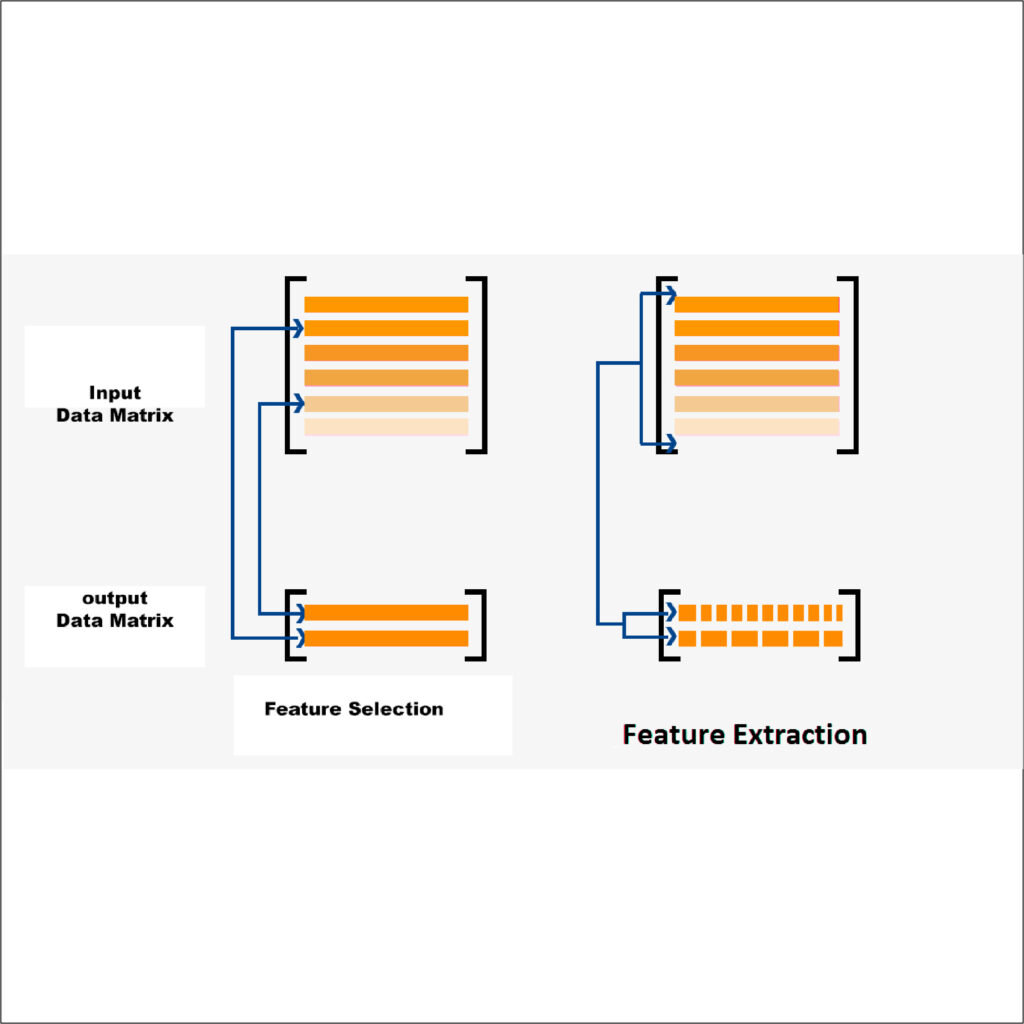
Feature Selection
This section will discuss the many ways you can select the right features. There are three main types of feature selection methods: Wrapper Methods, Filter Methods, and embedded Methods. The filter Method is independent from the algorithm, and features are chosen based on interactions between the features. The wrapper method, however, is not a preprocessing step in which the learning algorithm plays a significant role. The Embedded Method employs various regularization techniques in order to select features.
Feature Extraction
There are many methods to perform feature extraction, including Kernel PCA (Principal Component Analysis), Kernel PCA (Kernel PCA), Linear Discriminant Analysis(LDA), and Independent component analysis (ISO), and Kernel PCA (Kernel PCA). This blog will discuss about the benefits of PCA. This method transforms features into a collection of artificial features. These “artificial features” are called Principal Components. The first component is the most important information and can only be found in one ‘artificial function’. We are free to choose how many components we want to reduce the number.
Factor Analysis
The correlation coefficient plays an important part in Factor Analysis. As a classification technique, Factor Analysis is also useful for feature selection. These groups are formed by the combination of highly correlated features that are not related to each other. There are basically two types of Factor Analysis: EFA (Exploratory Factor Analysis) and CFA (Confirmatory Factor Analysis). This blog will explore the use of factor analysis as a feature selection tool.