
Multicollinearity is a problem that is the main issue in data modeling- overfitting. The reason for this is the presence of correlated features. In most cases, the volume of data available is overwhelming due to numerous features, which makes exploring the data very difficult. The huge quantity of data comes with many disadvantages; for instance, it can increase the time to compute, reduce the storage space, and, perhaps most importantly, cause multicollinearity, which can cause models to be overfitted.
Dimensionality Reduction aids in reducing processing time and enabling us to execute more complicated algorithms. Another benefit of keeping the data in a smaller size is that it allows storage space. These advantages are, however, all hardware-related. One of the most significant benefits that come from Feature Reduction is that it addresses the issue of multicollinearity.
This is why Dimensionality Reduction can help make an analysis of information more efficient and more precise.
The two most commonly used methods with an Unsupervised Setup that can be employed to reduce the information size include Principal Component Analysis and Factor Analysis.
Principal Component Analysis is where the information from the high-dimensional area is reduced less dimensions. In simple terms, we transform our data into fewer artificial ones without losing a lot of the data.
Factor Analysis Features are grouped according to their similarities, which their common variance will determine, and then the user can select the most relevant features from these groups. This makes the feature set distinct and less susceptible to multicollinearity.
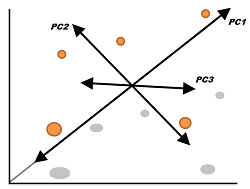
The elements are transformed into an array of artificial features. These artificial features are called Principal Components, in which the first component is the most important data that can be included within a single “artificial characteristic. We have to choose the components to be included to minimize the number of features. The features aren’t explicitly eliminated; rather, the variations are extracted, thereby avoiding the information.
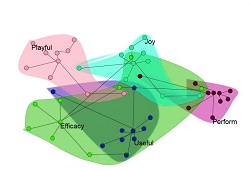
The correlation coefficient plays a significant part in the Correlation Coefficient in Factor Analysis. A classification method called Factor Analysis can be utilized to reduce dimensionality. The groups are formed by combining highly related features in which the groups aren’t related to one another. There are two primary kinds of Factor Analysis- EFA (Exploratory Factor Analysis) and CFA (Confirmatory Factor Analysis).