
The HTML0 version of Neural Networks is among the most advanced methods to address Regression as well as Classification problems. The process in Neural Networks is inspired by the human brain, which comprises billions of neurons.
Evolution of Artificial Neural Networks
Phase 1
Artificial Neural Networks first came into employ in the 1940s as Warren McCulloch and Walter Pitts’ research paper “A Logical Calculus of Ideas Immanent in the Nervous Activity (1943) built models that functioned the same way as humans’ brains do. The early designs were built on a single neuron’s functioning, including a trigger function. These models served as a great beginning point; however, these models were able to solve very simple problems and weren’t useful in the long run. The invention of artificial neural networks was placed into cold storage following the publication of Perceptrons: An Introduction to Computational Geometry’ written by Marvin Minsky and co-authored by Seymour Papert got published in 1969. The book exposed the limitations of neural networks at the time could only handle linearly separable problems and could not solve simple boolean issues like XOR as well as NXOR functions. Marvin Minsky and Seymour Papert declared that their research on perceptron was destined not to succeed.
Phase 2
The research began in the 1980s when researchers discovered two factors: One was the understanding of putting several perceptrons in one, and the second was backward Propagation. However, the ability to apply Neural Networks to achieve success was only available to extremely limited resources and couldn’t be utilized by everyone. Additionally, the method was expensive to compute, and the computers of that time could not be utilized. The development of other successful linear techniques like the Support Vector Machines developed by Hava Siegelmann and Vladimir Vapnik caused an end to the development of Neural Networks.
Phase 3 (Present)
The Neural Networks resurfaced in 2013-2014 primarily due to the advancements in computer hardware that led to the rapid growth in the processing speeds of computers that enabled the use of computationally intensive neural networks to be feasible.
Why Neural Networks Stand Out
The fundamental equation for every machine learning algorithm, For instance, the problem of classification, can be described as Y = sign(wx + b). In this case, Y is the expected value, and x represents information input. Then, we have the weight w, which is weights. We need to determine whether it is higher than 0 or less than. The sign is removed, and we’re left to determine the value of the weight, which will influence the expected value. But they heavily depend on the correct feature set and can be difficult to determine in situations with a different kind of data, such as that for multimedia that has an entirely different feature that is not included in the features we have; that has been discussed previously.
If, for instance, you have an audio tape that cannot be used as an x-variable since the model will not learn anything. So, to transform x, we require a vast amount of knowledge about the domain. If, for instance, there are ten pictures, we cannot simply take the intensity of the pixels as data and then use these as variables for x since we aren’t sure which characteristics represent curvature, edges, colors, basic shape, etc. To do this, we’ll need to implement edge detectors, for which a deep understanding of the domain will be necessary.
So, we require a universal algorithm that is able to comprehend all types of data, regardless of whether the source is audio or image. In this case, it is interesting to pose the question of how children who don’t possess “in-depth field knowledge” about the geometrical features of fruit are able to identify one fruit from the other. The answer lies within our brains, which can turn all information into features that can be interpreted and understood by a universal algorithm. This algorithm is called a neuron.
The process of forming this kind of learning algorithm is like teaching a child to recognize different fruits. We begin by telling them the what. Once explained, we continue asking them about it and continue to correct them until they’re in a position to recognize patterns that will result in more effective outcomes.
Parallels Between Neurons and Artificial Neurons
Working of Neuron
To fully comprehend the way the Artificial Neuron works, it is essential first to understand the way the Neuron operates and draw parallels between them.
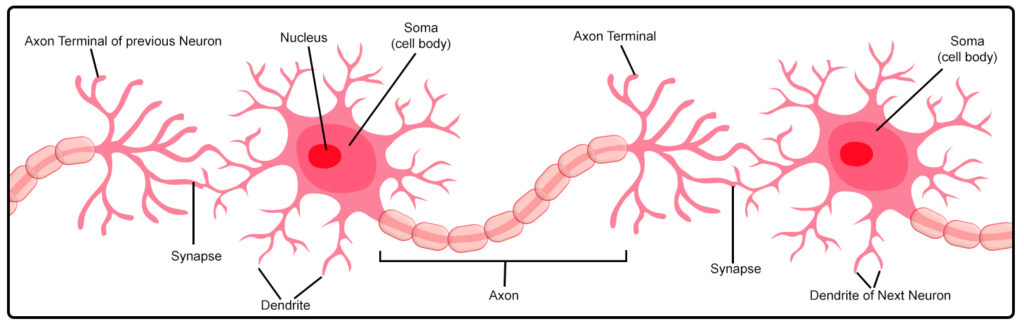
Structure of a Neuron. Neurons connect to each other to form Neural Networks.
Humans don’t require the representation of features because we have cells within our brains that are known as neurons. Every neuron is a part of an internal body, wherein the middle is the nucleus. The cells (Soma) have a tentacle-like structure that protrudes out in different directions that are known as dendrites. From the Soma, one of these dendrites gets elongated along the direction of a particular direction and is referred to by the name of the axon. To fully comprehend artificial neural networks, we have to know the functioning of these elements of a neuron.
Dendrites are sensitive to specific chemicals, and when they absorb chemical compounds, they produce a chemical signal transmitted to the nucleus. A chemical that is stronger than the dendrites triggers them to produce a stronger signal. Likewise, when the intensity of the signal exceeds an arbitrary threshold, the nucleus will emit an electrical signal. The electrical signal is carried through the axons to the Axon terminal. When it is at the Axon terminal, the signal initiates another chemical reaction. The axon tips release chemicals in the synapse, which is the space between two neurons. The chemical is received by the dendrites of the neuron that is opposite.
The entire process is repeated. If it is strong enough to overwhelm the nucleus in the neuron, it starts firing, which is later received by another neuron, and so on. However, should it not generate a sufficient signal that the other neuron does not activate? This is why the amount of chemicals and the threshold at which the nucleus begins firing are key in the production of electrical signals. A human brain can produce enough of these electric signals to produce enough power to light the bulb with a 25-watt power source.
Artificial Neuron and parallel between Neurons and Artificial Neuron
In order to understand neural mechanisms and their functions, we can construct a mathematical model. This mathematical model that is based on human neuronal activity is what creates an artificial neural network.

Structure of an Artificial Neuron
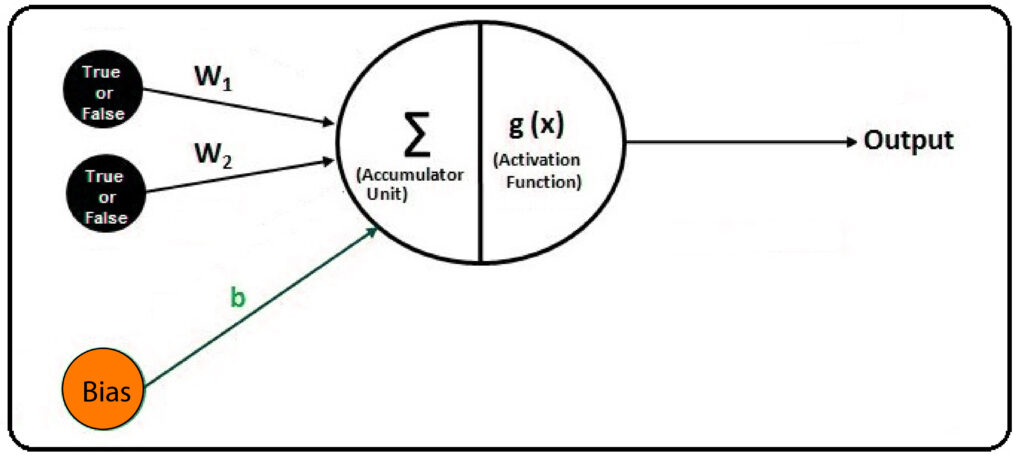
For instance, we’ve got an issue with classification with five variables ‘x’ that will serve as the input variables. The value of these variables, x, is put into an accumulator unit’. The accumulator unit combines the values of the input variables in order to figure out the amount of ‘chemical’ in the. So, it does the summation and ends up with a number.
We have reproduced the chemicals and dendrites. Now we require something that is similar to the nucleus that is found within the neurons. To duplicate the mechanism that fires the nucleus, we utilize something called the activation function. There are numerous activation functions. In this instance, for instance, we look at an activation function that squashes (sigmoid) that squashes activation function in the range of 0 to 1 and uses the threshold value. In other words, if the value falls less than the threshold, it is fired 0; If it’s higher than the threshold set, it goes to 1.
An activation device, when constructed on a sigmoid model, will be represented by an equation g(z) = 1 (exp(-z)) / (1 + exp (-z)) where Z is the value supplied by the accumulation unit. The activation function produces a Y value that is dependent on the variables x and weights as well as bias. The Y here is considered as an electrical signal generated through the nuclear nucleus.
Weights are also used as inputs in an accumulator system. The reason for using weights is derived from dendrites that have various strengths to capture the chemical (x variables). Thus, if a particular dendrite’s power is high, it will produce a high signal, and vice versa for the same signal that an x parameter has. The strength of dendrites can be seen by using weights in which each input variable is assigned weights, and the values of the input variables are multiplied by their weights to replicate the effect of different dendrite strengths.
So far, we have identified the chemical (input variables), multiplied them with the dendrite strength (weights), and then added the results using an accumulation unit. We also include the bias term. For a classification binary challenge, the term bias is easily identified as a negative amount that limits the input value that it has to be crossed to get from one class to the next.
All this information is passed directly to an activation process that decides on the behavior of fire. This is how we have the equation that will determine artificial neurons, that is
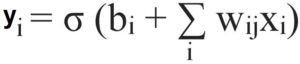
Interestingly, we have input variables, a squashing function (sigmoid), and output Y, a squashed variant of a weighted total of inputs. It is the same as logistic regression. As of now, we’ve been able to accomplish the same results that logistic regression could achieve.
Limitation of Artificial Neuron
We have so far developed an algorithm known as the Single Layer Perceptron, where we only use a single Neuron. This is the place at the time of its inception, around 1940. To better understand the limitations of a single neuron, we will investigate and try to solve the simple boolean equation that can’t be solved with one neuron, as Marvin Minsky and Seymour Papert suggested in their book “Perceptrons.” This boolean issue is known as XOR.
The most fundamental idea we can get from the guideline is that one brain can only solve linearly solvable issues and, for instance, if we have information for 28-pixel images that have handwritten numbers ranging from 0-9, which would give us 784 features (28 27 x 28 is 784). We apply these 784 features to define the 10 digits. If the data points we have aren’t separated, the neuron won’t be able to aid anyone in any way.
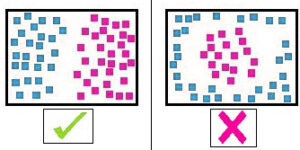
On the left are Linearly Separable Data Points, while on the right are Non-Linearly Separable Datapoints.
In the real world, many issues can’t be solved using linear separators. To illustrate this, we’ll look at an XOR problem.
If we are required to construct the ‘Truth Table’ with the boolean operator “and” (&&) and then, we must be aware that True and True = True False and True = False True and False are False, while False and True equal False.
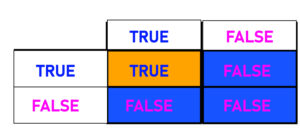
If we now have a boolean equation ‘A and& B’ and in order to be true, we need both the expressions: A or B, to match to be the correct answer. It is really interesting to note that this is a linearly separable issue since each False is on one side, while True may be on the other (i.e., If A is true, B is True, for instance, that A is age 25 while B’s Balance is 50 If Age isn’t 25, but Balance equals 50, then it is false. If the Age is 25, but Balance is not 50, then it’s false. Suppose the balance and age are not the same, and therefore False).
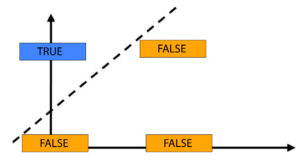
So, if we need to build an individual layer perceptron, we can accomplish this by using two input variables, True and False. Then, we can train the model so that when two trues are found; we’ll have a true; when we have other falses, we’ll deal with the false (True False, False True, False False).
If we alter the boolean expression we use to be B,” i.e., instead of using the boolean operator “and” (&&), include ‘or,’ (||). The table of truth is altered; however, it will remain linearly separable, meaning that we can use only one neuron to solve this issue.
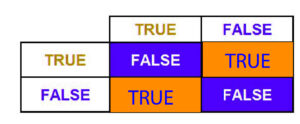
(i.e., If either A or B is true, then it is True. For example, if A is age=25 while B has a Balance = 50, If Age is not 25, and the Balance equals 50, then it is true that Age is 25 and the balance is not 50. is it true? If both Age and Balance are 25 and 50, then it is true, but only if Balance and Age aren’t 25 or 50, then it is false).
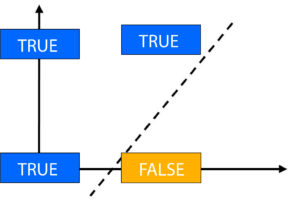
If, however, we have an XOR boolean operator, which is a reference to ‘Exclusive OR, which is a way to determine True, we require an expression that is True while the other is False. If both are true, the result is False, and if both expressions are false, the result will be false. Therefore, only if one of them is true and the others are false will we be able to get accurate. As we build our truth tables, it is possible to observe that the problem is not separable in a linear way.
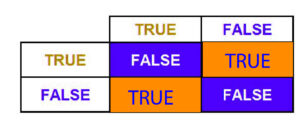
(i.e., For example, if A is 25 years old while B has Balance=50 and if Balance is 50, then Age isn’t 25, and the Balance equals 50, then the truth is that age is 25, but Balance is not 50. If this is true, the balance and age are 25 and 50. This is true, but if Age and Balance are not 25 or 50, then it is False).
Since both the Trues and False aren’t on the same side, we can’t draw a line that will effectively classify them. To do this, we have to draw two separate lines that will allow the trues to be between the two lines and the false to lie on the opposite sides.
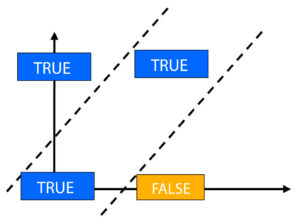
So, a single brain can’t solve a simple boolean problem. To tackle this issue, we must add another neuron. This brings us to stage 2 of neural network artificialization, where we were taught to connect the neurons to create multi-layer perceptrons, which are able to perform more complex tasks and manage non-linearly separable data.
Deep Neural Networks (multi-layer perceptrons)
XOR Problem
If we employ several layers or levels of perceptrons, then networks are referred to as deep neural networks. The term “Deep learning” originates from this and refers to networks that include hidden layers. To resolve the XOR problem, we’ll opt for a three-layer model, instead of the two-layer model we used in the past. In this model, we’ll have the input and output layers, as we did above. Furthermore, two additional perceptrons are inside the hidden layer, located between the input layer and the output layers. We are not able to view the inner workings that take place in the invisible layer. This is why they are named so that we can only see the input and what we get as output, while the majority of the processing of data is performed inside these layers.
If we attempt to solve the XOR problem again, but this time with more than one layer of perceptrons, we can successfully identify the issue.
If we add a layer to the network that was previously constructed, that means we’ll be able to have two inputs. Two neural networks in the hidden layer, one of which can answer the logical ‘or’ (||) while the other perceptron performs the opposite of the logic of “or” (||), or we could claim it’s a “not and” (!&&). Each input is then sent to both perceptrons, and the result is transferred to the perceptron on the output layer that performs a logic-based “and”. So if we wish to produce True to the result, the first neuron solves True “or,” while the second one will discover the True not, which will then result in the True XOR as these two are the only possible scenarios where “or” and “not and’ are True. So when both are true, they both get to the output layer perceptron that can perform logic ‘and.’ As they both are True, the output perceptron output is True.
For instance, we have input x1: B, and as output, the input is x2. The input is the first to reach the first perception point of the hidden layer, which functions as an operator with the ‘or. We have AB, which is a true ‘or’; as a result, the input could be BB. (the four possible inputs are A, AB, BA, and BB). This perceptron has the ability to get rid of the BB. But, to find the correct answer, we need to separate AA as well. To do this, we employ an additional perceptron. If the signal AB gets to the second neuron in the hidden layer that performs “not” and it discovers that it’s not and otherwise, the input could be AA. Together, they can remove AA as well as BB. The output of these perceptrons is transferred to the output layer perceptron, which is responsible for the logic “and.” To produce True it is necessary to have the words ‘True in addition to True’. Because the output of both perceptrons in this layer is True, we have an output that is True and can resolve the XOR problem by introducing a perceptron layer.
Practical Exercise
If we’ve denoted true for 1 and false zero and have the following dataset, then we can create multi-layer perceptrons.
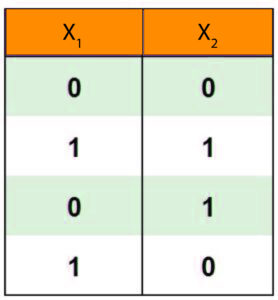
We employ a three-layer model that is, in the hidden layer, we can have 2 perceptrons, h1 and h2 along with a third perceptron called y in out layer. We apply the following bias and weights to the perceptrons.
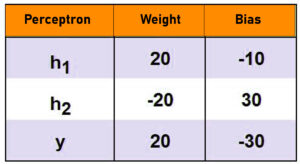
Now, we can visualize the three-level neural network.
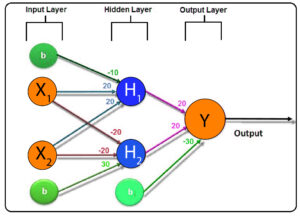
Structure of 3-Level Artificial Neural Network
For each perceptron, we’ll do the following formulas.
We add the data to the weights for the four entries and then add bias. In order to activate the function, we employ a very easy step function, where the negative value produces zero, while a positive value results in 1. We can get this result by using the weights, bias, and activation functions.
It is evident that for the values 0,1 and 1,0, we can achieve True as a result. This is why the concept of Multilayer perceptron connects multiple perceptrons in order to solve non-linearly separate and complicated problems. It is also important to identify that until now, we have talked about the feed-forward method where all connection is in one direction, without any cycles. In Feedforward, the input data from an input device is transmitted onto the subsequent layer in the unit. And after the necessary calculation, the result is then passed onto the next layer and on and so on until the final results are computed at the layer that outputs the results.
Repropagation (Backward propagation of errors Using the Gradient Descent)
Regarding how our brain functions, it was previously mentioned that to help a child learn the distinction between apples and oranges, it is possible to provide the child with many different pictures and then give him the correct answer to allow the brain to adapt to the situation every time it comes up with an incorrect answer and be taught to recognize the distinction between the two types of fruit.
A similar concept is employed for Backpropagation ( Backward Propagation of Errors) which was the second most significant aspect of Phase 2 of the development of Artificial Neural Networks which caused its revival. The principle behind Backpropagation is that we first give random weights and biases to the neural network and let it run for one cycle, after which we evaluate the neural network’s performance with the actual results. Based on the severity of the error, we modify the biases and weights of different perceptrons to achieve better results.
It is essential to recognize that, unlike the conventional models we’ve learned, Artificial Neural Networks work more like a black box since we don’t know what it takes to achieve the desired outcome, which makes it difficult to make a well-informed choice about how to tweak the algorithm to achieve more effective outcomes. In the previous example, we could understand what each perceptron was doing and how they were capable of solving an XOR problem. However, with hundreds of perceptrons, features, and layers, it’s impossible to know what’s happening in the layers hidden within the model and the role each one plays in solving the problem.
Therefore, we are able to modify the biases and weights in accordance with errors until we have the combination of these weights and biases that provide us with the highest quality results. After calculating errors, the algorithm runs in reverse, updating the biases and weights for each layer (hence the term “backpropagation”), and then it runs to calculate the error. It repeats the process until the error has been reduced.
We have already discussed the fundamentals of neural networks. The neural networks work by having vectorized input data passed between layers to others. We execute the matrix operation at each stage, multiplying each input with the appropriate weight. We then add an additional bias term, and then apply an activation algorithm to the result and then pass it to the following layer that performs the same calculations. The output of the previous layer, which is known as output, provides us with a prediction that can be used to calculate the error. This is accomplished by determining the difference between the predicted and actual value.
The error is used to calculate the partial derivative relative to the bias and weight in every layer. This is done by connecting an input layer to the output, and it’s done repeatedly; as a result, we can change the biases and weights and then continue to run forward with the latest biases and weights and calculate the error. We then repeat until the lowest error is identified. So, we can modify the biases and weights using backpropagation to minimize accuracy in our output; however, each iteration could take quite a long time, particularly when there are several hidden layers and the number of neurons within each layer. This is the main reason to explain why phase two concluded.
To gain a deeper understanding of backpropagation, refer to the blog
ARTIFICIAL NEURAL NETWORKS – BACKPROPAGATION
Computational Cost
As we discussed at the start of this post, the development of neural networks stopped when the first multi-layer perceptron structure and forward propagation. This was due to the absence of processing power since this network could get complicated extremely quickly. For instance, if we have two inputs, 0 and 1, we’ll have four different variations of the variables 01, 00, 10 01, 00, 11, and 11. Ideally, there should be 4 neurons within the hidden layer, where each one can decode a specific kind of combination. But, if we’re dealing with 100 variables, that means that we’d require two 100 neurons in the hidden layer to create predictions. Because of this structure, the neural network could become very complex. In advanced stages where there are several hidden layers, with each layer specialized in identifying a particular pattern, the procedure combined with backpropagation is extremely complicated. This led to the end of phase two, and it wasn’t until recently, when the advent of high-performance computing machines, that ANN was revived.
Activation Function
We’ve discussed the step technique briefly, and then we have looked at the sigmoid activation process in depth. Still, there are a variety of activation functions that can be utilized, each with specific particularities.
Step Function
Also called”Transfer function,” it’s the most fundamental type that activates. In this case, the threshold is set to zero. When the output is greater than 0, the neuron releases 1 (i.e., it is active); however, if the amount for the output value is lower than 0, the neuron produces zero (i.e., the neuron does not activate and therefore isn’t activated). But, this method only works when we have an issue with binary classification and is seldom employed.
Linear Function
This way, the output value will be passed through the following layer without manipulation. This function is just straight lines where the output produced by activation is proportional to the value that is generated by the output layer. But, it is afflicted with one major disadvantage: it does not have an upper or lower bound, and more importantly, it doesn’t create any nonlinearity. If all layers are activated through a linear function, the function that activates an output layer can be described as simply an equation of the inputs from the initial layer. The result is that having several layers is useless and creates a risk.
Sigmoid Function
The topic has been discussed in depth; the sigmoid/logistic activation function is a squeezing operation that causes the output between 0 and 1. This is in contrast to the linear function, where values could be anywhere from the -inf range to inf. It also introduces nonlinearity into the network and grows continuously by increasing the value, which results in higher activation results. Although it has its merits, it has an issue known as vanishing gradients. Suppose we examine the function’s graph and then observe that on both ends, the y values react less to changes in the x. That means that when you run backpropagation, when the activation value is located at these ends of the graph, the gradients produced will be extremely tiny, preventing any major changes in the weights.
Hyperbolic Tangent (Tanh) The function
It is out of the most frequently used activation functions. In contrast to the sigmoid function that doesn’t use 0 as the central point, the hyperbolic activation function is able to squash the output from -1 to 1 to create steeper gradients making backpropagation more efficient. Similar to the sigmoid function, it introduces nonlinearity to the network; however, it suffers from the issue of diminishing gradients.
Rectified Linear (ReLu) Function
It is the most well-known activation method that is widely used. It has the lowest limit, which is zero, where for any negative value, it allocates a zero; however, it does not have an upper limit and can extend all the way to the end of the universe, making the activation ‘blow up.’ Relu introduces a degree of sparsity into the network, which means that 0 is only assigned in the event that the number is positive. This results in a lack of activation that reduces processing time compared to sigmoid or Tanh, in which each activation is processed in a limited manner; only those activations are considered non-zero. Relu introduces nonlinearity to the network and does not suffer from the problem of diminishing gradients. However, it is afflicted by the issue of “dead cells due to the horizontal flat line on the graph that is present for neurons producing negative values, during the backward propagation, the gradients of these neurons could be shifted towards zero, making them insensitive to any change in the error. Due to the low gradient, they are not responsive to backpropagation and cause the “dying ReLu” issue.
This issue is resolved using different variations of ReLu, like Leaky ReLu PReLu, Maxout, etc.
Then, in Leaky Relu, we introduce a small slope, i.e., a non-horizontal component of that previously vertical line resulting in Y=0.01x for x0. This means that we can allow the possibility of a minor non-zero gradient even when the neural network is not active. Another variation of Leaky ReLu is the Parametric ReLu (PReLu), in which the idea behind Leaky ReLu is extended by turning leakage coefficients into a parameter learned in conjunction with other parameters of the neural network. In this case, Y = ax for x0. Another function referred to as Maxout is a mixture of ReLu and Leaky.
ReLu is the most frequently used activation method; however, it should only be used on the hidden layers. Linear Function should only be employed on the output layer when dealing with Regression problems. SoftMax (functions for squashing) is recommended for the output layer when dealing with classification problems.
So, many activation functions could be employed when creating a neural network. It would be the best thing if you remembered the importance of the activation function. Crucial because without functions, the output from the layers will result in a straightforward linear function, which will eventually cause the neural network model to behave as an equation model. As we mentioned in the first paragraph of this post, we wish for that our model of neural networks behave as human brains that are able to operate with any type of data, making them Universal Function Approximators, meaning that they are able to represent functions made up of various types of data (audio-video, images, and so on.) and be able to learn and compute any function. In order to do this, we need the model to be complicated enough not just to compute linear functions but also to learn more complex functions. To do this, we introduce various activation methods and include numerous hidden layers. Additionally, as we mentioned earlier, activation functions like Tanh and Relu offer the necessary nonlinearity of the model to create a differentiable model, allowing backpropagation to work properly.
An artificial Neural Network is the first step toward understanding the inner workings of different models that relate to Deep Learning. ANN gives us extremely precise results, but it’s computationally expensive during the initial training period, but it is quite fast in the testing phase. It should be utilized especially for solving extremely complex problems.