
DB Scanning is a density-based spatial clustering method known as Density-Based Spatial Clustering Applications with Noise. It can handle outliers in data and create clusters with arbitrary shapes. Clusters in DBScan are formed by linking data points located in densely populated regions.
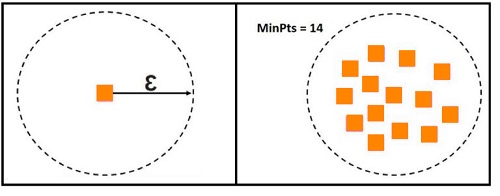
Epsilon & MinPts
E is the most important parameter for DB Scan. E is the radius around a neighbor of a datapoint, while MinPts indicates the minimum number of data points required to be in a neighborhood to make it dense enough to be considered a cluster. E determines the radius of a circle, while MinPts determines the minimum number of data points required to be in that circle to make it a cluster.
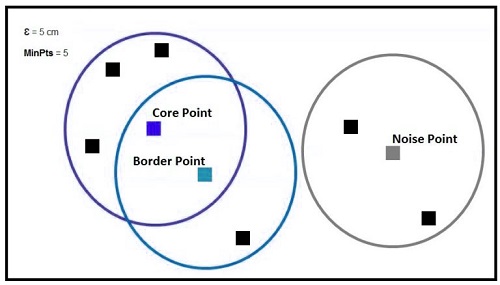
Border Point, Core Point, and Noise Point
DB Scan can categorize data points into Core Point (Border Point) and Noise Point (Noise Point). When a Data Point has the minimum MinPts for its E neighborhood, it is considered a Core Point. A Data Point can be classified as a Border Point if it does not have the minimum required data points but has one or more core points in its E neighborhood. A Data Point is considered a noise point if it does not have the minimum number of points or a core point within its E neighborhood. This data point is considered to be an outlier in data.
Below, we can see that E=5cm, MinPts=4, shows the Blue Square as the core point, Green Square as the border point, and Grey Square as the noise point.
Creating Clusters using DB Scan
Using the above concepts, DB Scan can create clusters by connecting neighborhoods. It is able to assign a cluster for data points densely situated in a region using clustering techniques. Clusters can be formed by selecting a random point that is not categorized. Once it has been identified as a core point, the algorithm assigns a cluster to the core points and their neighbors.
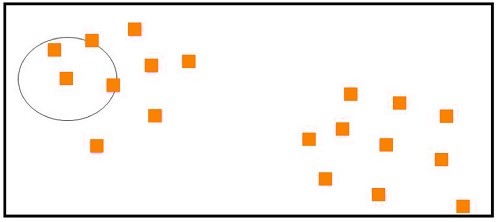
The Min Pts in the above figure is set to 3. This means the randomly chosen point is considered a core point because it has 3 data points within its E neighborhood. This data point, along with the data points within its neighborhood, is given a cluster label “A” (Blue Square). To find all density-reachable data points, the algorithm “jump neighborhoods” and assigns them the identical cluster label, i.e., We determine if the data points beyond the core point’s reach are core. If they are core data points, then all data points in the neighborhood are also labeled with the same cluster label.
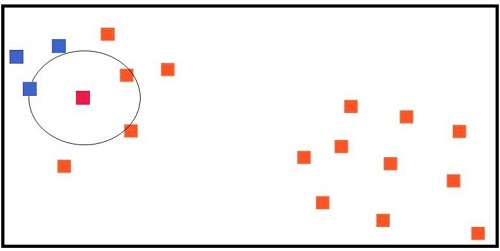
This is done for all data points. A cluster is formed when strings of density-reachable data points can be found in areas where A is directly density reachable to B, and B is directly identifiable to C.
The image below shows the neighborhood for all data points. Core points are in red, and the border is in green. Outliers are in grey.
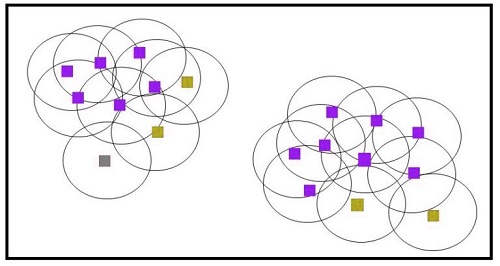
We can now create two clusters, while outliers are excluded from any clusters.
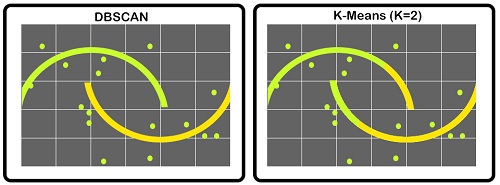
DB Scan works well when there are outliers in data. Unlike K Means, it is not affected by outliers. DB Scan can be used to find clusters of different sizes and shapes. This is a typical example: If data is in the shape of a half-moon, where K is because of noises, DB Scan is unaffected.
It is important to consider the parameters. A low E means fewer points are directly density reachable, and therefore, less clusters can be formed. However, a high E means that many points become density reachable, which could cause outliers to be included within the clusters, and dense clusters of data points to merge. DBSCAN does not work well with data in high dimensions. It is, however, faster than many other clustering algorithms (such as K-means) and should be used when there is noise.