
Clustering can be described as unsupervised learning in which we don’t have any Y variables. We don’t attempt to predict anything because we don’t have any Y variables. Clustering is simply a way to look at our data and find patterns. These patterns generally indicate the possible number of groups or data types in the dataset. Clustering is a way to determine the number of “clusters” or “sub-populations” in our data. We can also examine each cluster in detail to learn the characteristics. Clustering methods, like K-Means or Gaussian Mixture Models, can be used to detect anomalies. There are outliers in the data.
Clustering is a process in which nothing is given to the algorithm to predict. Instead, it runs and generates clusters of data that are similar. This algorithm differs from the Supervised Learning setup in that the user does not have any control over how or on what basis clusters are formed. It cannot be used to predict anything, unlike the other algorithms.
There are many ways to categorize clusters. There are two types of clustering algorithms. The first is hard clustering, where each datapoint is assigned a cluster. It belongs only to that assigned cluster. Fuzzy C-Means clustering is an example. Soft Clustering, on the other hand, doesn’t assign data points explicit clustering labels but gives a range of data points that belong to each cluster. A data point may belong to either cluter_1, cluster_2, or 10% of cluster_3. Another classification is whether the algorithm uses flat clustering or hierarchical. Flat clustering is simply a method of dividing the data space so that different clusters end up with data points. Hierarchal clustering, on the other hand, works in a similar way to a tree structure. Each group of data can then be further divided into smaller groups. This can be continued until sub-groups cease to make sense. Suppose we have a data set and perform hierarchal clustering. We find two categories in the data, the first being beverages, and the second solid, fast food items, and decide to split the groups further. In that case, we might end up with another set of groups where we know which types of beverages (such as soda, juice, etc.) and what fast foods (pizza, doughnuts, etc.). There are many ways to classify clustering algorithms, including Hierarchal based methods and Partitioning-based methods. We also have Grid-Based Methods, Model-Based, Density-based, and Grid-Based Methods.
Clustering algorithms are the most well-known.
(Partitioning Based)
K-means clustering, K-medoids clustering, K-modes clustering, K-D Trees, PAM, CLARANS, FCM
(Hierrarichal Based: can be agglomerative(bottom-up) or divisive (top-down)
BIRCH, CURE ROCK, ROCK, Chameleon, and Echidna
(Density-Based)
DB Scan, OPTICS, and DBCKASD. DENCLUE
(Grid Based)
Wave-Cluster, STING, CLIQUE, OptiGrid
(Model-Based)
EM, COBWEB, and SOMs
(Other Methods)
Gaussian Mixture Models, Artificial Neural Networks and (ANN), Genetic Algorithms like a GGA (Genetically Guided Algorithm),
There are many clustering algorithms one can look at. Below are 3 types of clustering algorithms: Hierrarichal Clustering, K-means, and DB Scan.
DBScan can be used to identify outliers and form clusters. Hierarchical clustering, which is visually based, allows sub-populations to be identified in the dataset. K-means is the most popular and easiest to understand, where clusters are created using centroids.
It is not easy to assess the effectiveness of clustering algorithms. However, there are manual methods that can be used to determine if the clusters make sense or if they are not. The size of the clusters can also help to understand the algorithm’s performance.

This is the most commonly used method of clustering. K allows the user to choose how many clusters they want to form. This gives the user some control over the learning process and provides supervision. K is used centroids to create data clusters. The most important role in this process is the value K.
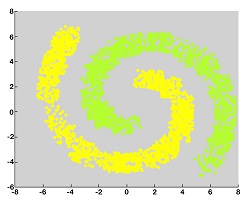
DBScan, also known as Density-Based Spatial Clustering Applications with Noise, is a clustering method that creates clusters and identifies outliers. DBScan is able to handle outliers, which can often be a problem in other clustering algorithms like K means. DBScan uses concepts like Core Point, Border Point, and Noise Point to create clusters.
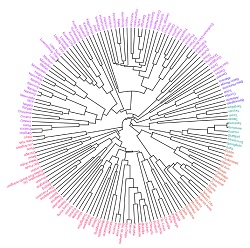
Flat Clustering is where the user does not pick a number of clusters, but the algorithm arranges data in a hierarchy. At the top, there is one big cluster, and at the bottom, there are many clusters. There are two possible approaches to hierarchical clustering: Agglomerative Clustering or Divisive.