
Supervised learning is a form of data modeling where we attempt to anticipate a certain type of value. In an environment of Supervised Learning, there is a labeled training dataset. A typical instance of a dataset could be (for an algorithm to learn classification) a set of data with dependent variables with discrete values such as “Spam” or “Not Spam. In this case, multiple independent variables are utilized for training a function in order to assist us in determining the proper values of the dependent variable.
The most significant benefit of supervised Learning is that the effectiveness of the learning algorithm can be evaluated by comparing its predicted results against the initial labels. Additionally, when using an algorithm to learn in a learning environment that is supervised, it is possible to increase the accuracy of the model could be improved through tweaking the algorithms to ensure that the output of the model will be similar to what actually happens.
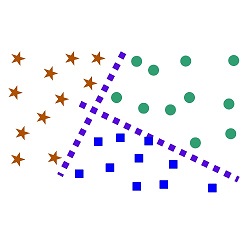
In contrast to unsupervised learning, however, the process of Supervised learning generally includes using a Training or Test dataset, where algorithms are trained to learn a specific function using a Train dataset and then tested using the Test dataset. The issues which can be solved in a Supervised Learning setting include Regression Problems and Classification issues.

When the dependent variable is comprised of continuous values, and these values can be predicted, then this issue is known by the term Regression Problem. In this case, the model’s output isn’t always accurate, but it is expected to be similar to the values of the initial model. The most popular method for learning to solve the issue can be described as Linear Regression followed by Decision Trees, KNN.
The concept is an evolution of One Way ANOVA, where groups of dependent variables can be compared to determine the extent to which they are statistically distinct from one another or not.