
Data Analysis may be of different types, ranging from simple data exploration to developing data models that use different machines and algorithms to accomplish different tasks like classification, prediction, etc.
In this article, the mathematical elements of the algorithms discussed are examined. The workings of different algorithms and their advantages and disadvantages are discussed. The data models are constructed in different environments like Supervised Learning, Unsupervised Learning, Reinforcement Learning, and many more.
For Supervised Learning, algorithms are expected to predict continuously-changing values (Regression Problems) or categorical values (Classification Problems). We divide the variables in the data into two general categories: the dependent variables and the independent (aka the response) variable. Within the Supervised Learning configuration, we are trying to create the relationship between the dependent and independent variables. We then design the algorithm to develop a function that predicts the values of dependent variables by analyzing those variables that are independent. It is possible to use Reinforcement Learning in which Artificial Neural Networks work. Still, because it’s very similar to the concept of Supervised Learning (the idea of having a well-labeled dependent variable can be found present when it comes to reinforcement learning), The algorithm has been incorporated under the umbrella of Supervised Learning only.
Unsupervised Learning Models are free of the need for any dependence (response) variable, and the algorithm is left to chart the course of its own and generate useful information. Here evaluating a model becomes difficult. Unsupervised Learning can be used to identify anomalies, clusters, and feature elimination.
Another type of model that is possible to create is the Time Series Model. They’re similar to problems solved by the Supervised Learning setup as values are predicted, but here, Time is considered the primary element in determining the value. The values for the coming timeframe are forecasted.
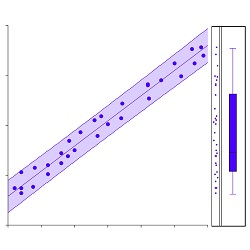
Most learning algorithms operate within the Supervised Learning setting in which the prediction process is monitored as the algorithm is instructed specifically about what it is expected to predict. The supervised learning system includes an independent variable that is well-labeled. This assists the algorithm learning in making predictions and assists in evaluating the outcomes.
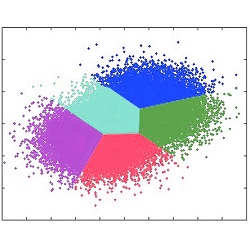
Certain models function in an unsupervised setting that has no labeled dependent variable, and the algorithm does not know or does not have the authority to make predictions about any particular. The algorithm creates patterns and patterns of data that aid in completing tasks like clustering, dimensionality reduction anomaly detection, etc.

Contrary to Supervised Learning, in which a labeled dependent variable is provided, or unsupervised Learning, in which the algorithms do not know what they are supposed to determine, Time Series models are developed when we need to forecast values over the course that is time-based, i.e., forecasting values. There are many methods of doing Time Series forecasting, such as Smoothing, Time Series Decomposition, ARIMA, etc.