
TYPES OF FEATURE SELECTION
Dimensionality reduction refers to reducing how many variables (features) are being reviewed. Due to the curse of dimension, many modeling algorithms can’t function properly in high dimensions. Reducing features can help reduce overfitting and increase the model’s accuracy. Dimensionality reduction can be broken down into two sub-categories, Feature Selection and Feature Extraction. This section focuses on Feature Selection.
A linear equation can help us understand how feature selection differs from feature extraction.
a + b + c + d = e
Imagine that a, b, c, and d represent the independent features and e the target variable. We can do so in two ways if we want to reduce the number of independent features.
First, ab = a+b can be equated, and we can use ab to signify two variables. This makes the equation look like
ab + c + d = e.
This is how feature extracting works.
If d’s value is zero or a small number, it is irrelevant to our equation. We can drop it to make the equation look like this.
a + b + c = e
This is how feature selection works. We select the relevant variables to our equation and exclude irrelevant features. This is how feature selection works. It eliminates irrelevant variables and selects features that improve the model’s accuracy.
The following blogs will discuss various ways to select the most important features.
There are three main methods by that feature selection can be performed. These are the Filter Methods (or Wrapper Methods) and the Embedded Methods (or Embedded Methods).
Wrapper methods use predictive models to score subsets of features based on their error rate. They are computationally expensive, but they provide the best results and allow us to use the features that improve our model’s accuracy.
Filter Methods require less computation but are more accurate than Wrapper Methods. Filter Methods are unique in that they produce features that don’t include assumptions based on the predictive model. This makes it useful for finding relationships between features, such as which combination of features decreases the model’s accuracy and which combination helps to increase the accuracy.
The embedded method mainly uses regularization algorithms to find features contributing to the model’s accuracy. It picks features at each stage of the model building process, thus ensuring the best accuracy.
These methods are all explored in the following.

Filter Methods
Different Inferential Statistics are used in Filter Methods to reduce the number of features. In order to reduce the number of numerical features, Correlation Coefficients can be utilized to establish the correlation between dependent variables as well as the independent variable. Different versions of Correlation Coefficients like MIC are also used in this regard. For Categorical Features, chi-square can be utilized. Other options are Linear Discriminant Analysis (LDA). But, all of these methods take a lot of time since each feature must be scrutinized separately, making the entire process of selecting features slow.
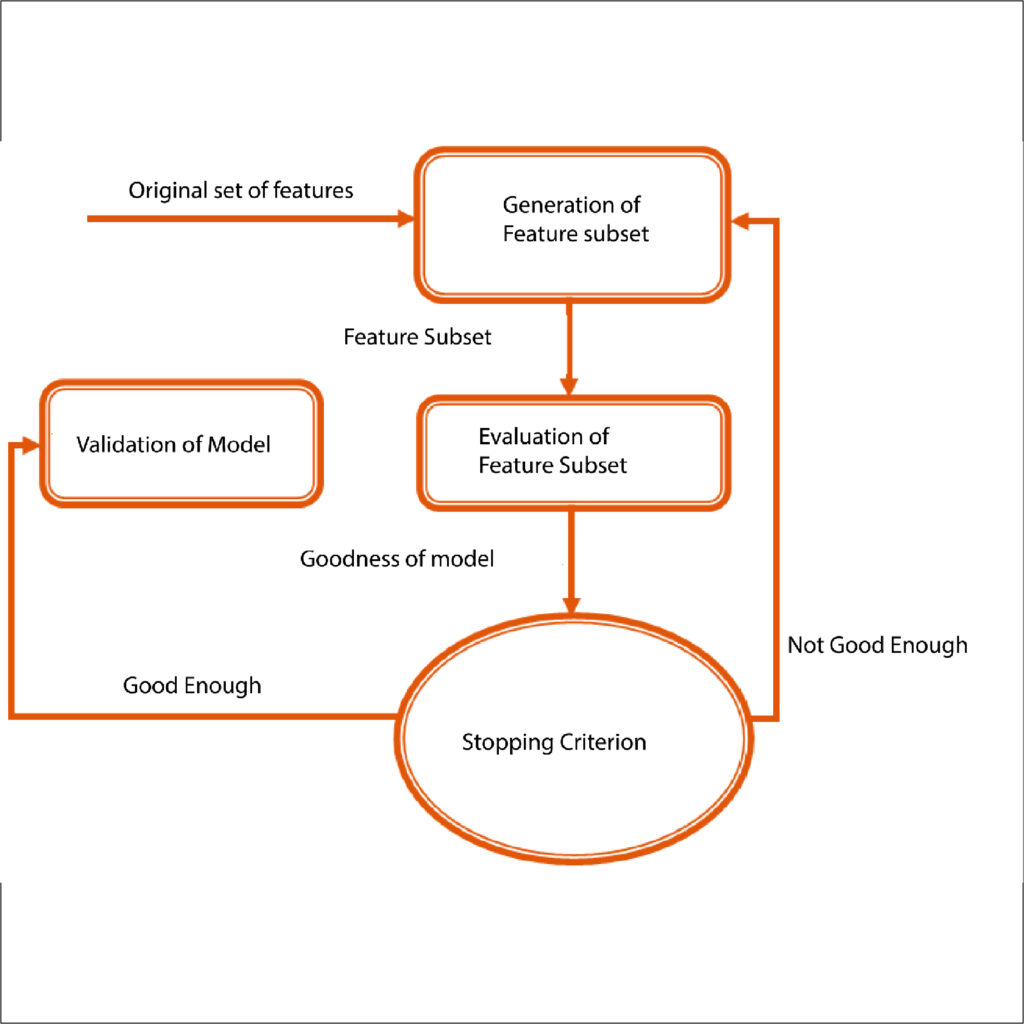
Wrapper Methods
Models can be utilized to limit the number of features. This is the reason behind the various wrapper techniques. One of the most popular wrapper strategies can be that of the Standard Stepwise method combined with forwarding Selection and Backward Selection methods. In contrast to Filter methods that require a lot of features, the entire feature set of the data set can be examined in one go using much less human input, making the entire feature reduction process faster and more efficient. Other options comprise Recursive feature elimination and Stability Selection.
Embedded Methods
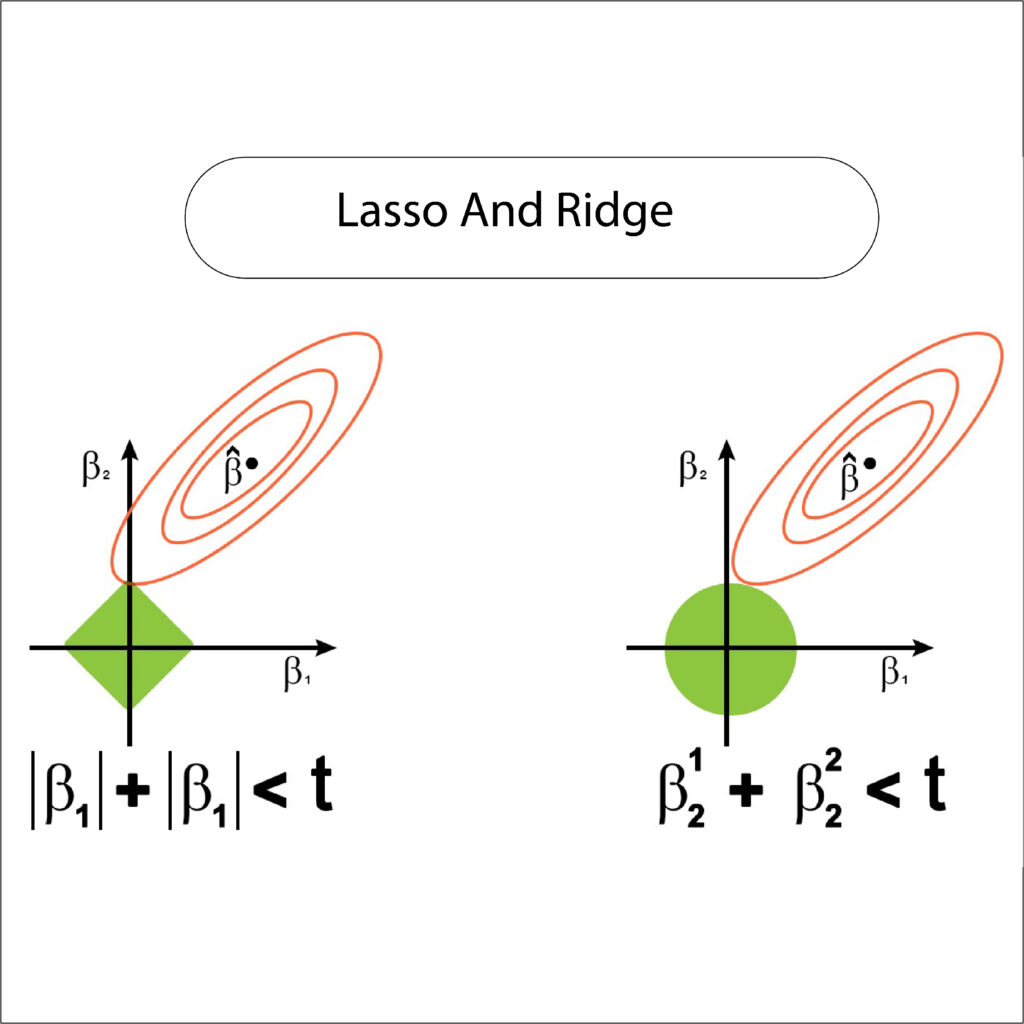
In the Embedded method, various methods of regularization are employed. The most commonly used method is Ridge Regression and Lasso Regression. In Ridge regularization, L2 distributes the coefficient value more evenly. So, features that have the lowest coefficient value are eliminated. Ridge does not cause any coefficient to shrink to the point that it is 0, which is what makes it different from Lasso, which uses regularization using L1 that allows specific features that have zero as coefficients. In this way, features with a non-zero coefficient can be selected.