
DIFFERENT TYPES OF ENSEMBLE METHODS
Ensemble refers to a set of things. Ensemble methods are groups of integrated models that can solve the bias-variance issue that is often encountered when trying to find the solution using one model. Ensemble methods are meta-algorithms that use other algorithms for modeling to help you learn an array of predictors.
These methods are a viable solution to problems that can be solved with Supervised Learning and Unsupervised Learning However, in this section, we will concentrate on using these methods to solve Regression and Classification issues that are solved in the context of a supervised learning system. Clustering problems are solvable using group methods referred to as Consensual Clustering and won’t be covered in this blog post.
Ensemble models can come in two types: homogeneous and Heterogeneous. When a model is Homogeneous, it is the case that only one induction algorithm is employed. This simply means that we use an algorithm for learning (such as Logistic Regression) and employ Cross Validation (generally k-fold cross validation) to build a number of base models.
Therefore, the Ensemble Model is called Homogeneous when the initial learning models are constructed using the same algorithm. Similar to that, Heterogeneous Ensemble Models are when we employ different algorithms for induction, which means that we use different methods of learning (such as the Logistic Regression KNN, SNN e) to create various bases models. In both cases, we create a set of predictors/classifiers, and we predict/classify the new data points (new data points of testing dataset or a new unseen dataset by combining the models (combine multiple predictors)) through algebraic or voting methods. In this case, for instance, we’ll apply a voting strategy when it’s a classified problem, like majority voting, in which we vote with a majority on the predictions of various models to classify the latest data point.
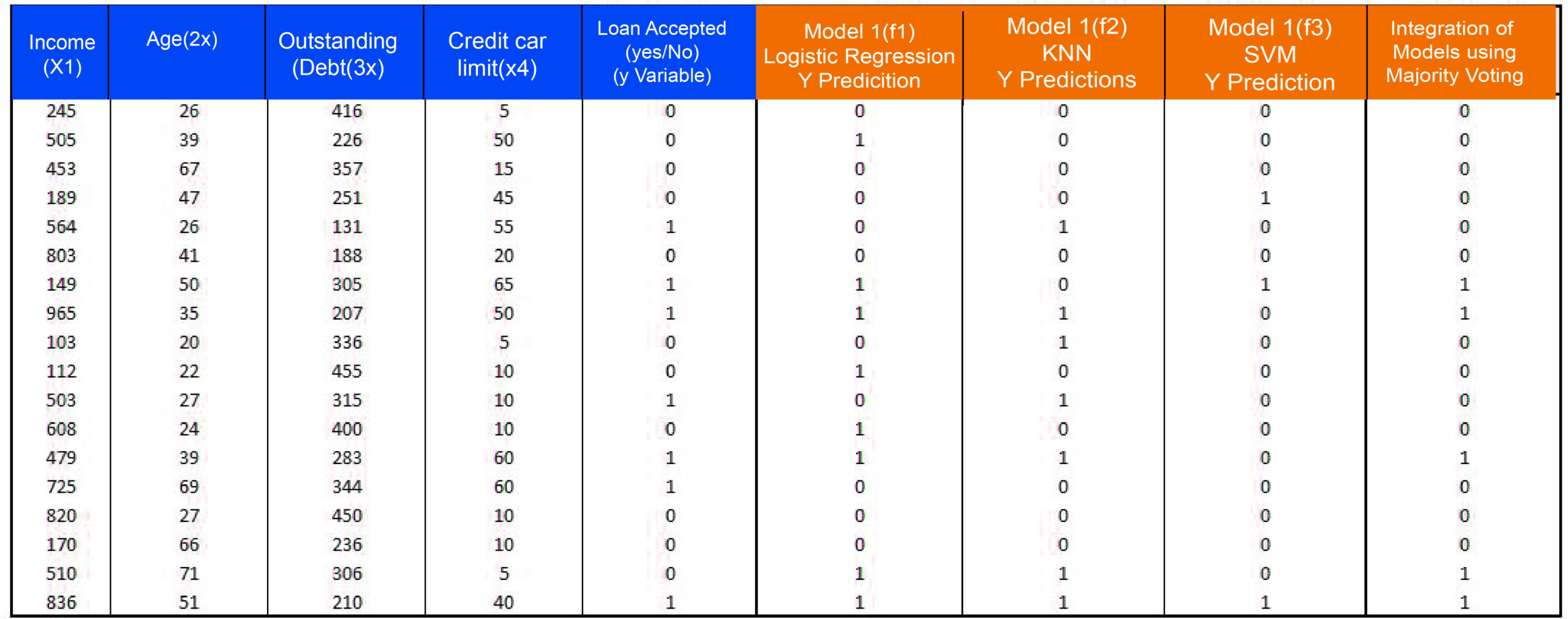
In the case of homogeneous models of an ensemble, it is possible to use this method of consolidating to join an ensemble of similar learners (as used in the bagging and increasing).
The Algebraic methods used to combine models used in solving regression problems are unweighted mean, weighted mean sum, weighted sum product maximum minimum, median, and maximum. When dealing with classification issues, the voting methods are majority voting, weighted majority voting, and Borda count. You can find the values of all these parameters, as well as that correspond to these parameters (for weighted average or majority) with the help of software like Python and R.
An easy way to comprehend all this could be
So the procedure for creating an ensemble model involves the following steps:
Step 1: Generating different base models (homogeneous or heterogeneous)
Step 2:A second stage of pruning in which some base models may be removed
Step 3:Incorporating a model using voting or algebraic methods
Step 4: Predict data points
Step 5: Perform Accuracy checks (Model Evaluation)

The wisdom of the crowd
The principle behind the concept of ensemble models is to employ various weak models to create an overall solid model. To grasp this concept when you are faced with a problem in your head, what’s most likely to be the very first action you take (or did prior to the introduction of Google) is to ask others for an answer. The more people you ask, the better your chance of getting the correct answer. In the event that you asked about an issue, say which is Google’s chief executive at the time of 2017 – Sundar Pichai or Satya Nadella. You asked 10 of your friends, and each has their own opinion; some said Sundar Pichai, while others said Satya Nadella. However, each opinion is weak when viewed in isolation, but after combining the opinions of your 10 friends, you’ll be able to determine an answer. If four of your peers favored Sundar Pichai and you rely on an easy majority voting, you may end up selecting Satya Nadella as the correct answer (which isn’t the right answer). It is possible to utilize weighted majority voting, where you add weight to the opinions of your friends seeking a degree in a computer science-related field. If you have four of your friends say that Sundar Pichai was from a computer science area and you can choose Sundar Pichai as the correct answer, that is right. In ensemble models, members are weak models. At the same time, the method for consolidating them can be either an algebraic or a voting method (depending on the nature of the problem – regression or classification). Therefore, the method used for consolidation is important because the predictors you believe are more reliable can be assigned more weights. However, models based on ensembles assume that more predictors are more effective than one predictor and can yield better results.
Types of Ensemble Methods
There are three kinds of group Methods-
Bagging: The prediction is averaged over a set of uncertain predictors that are derived by bootstrap sample data (Homogeneous Ensemble Method for Classification and Regression Problems)
Boosting: It enhanced weighted vote using a set of classifiers developed sequentially using training sets that prioritized instances incorrectly classified.
(Homogeneous method of the ensemble to solve Classification Problems)
Stacking: Combining the predictors of a variety of heterogeneous types.
(Heterogeneous ensemble method to solve Regression, as well as Classification Problems)
Ensemble learning systems employ the concept of ‘wisdom from the crowd.’ They can create extremely effective models that have higher forecasts than what a single model could have. Today Ensembling techniques are widely used, and various other methods of learning in an ensemble need to be studied.
Other techniques for ensemble include a Mixture of Experts, Bayesian parameter averaging, Bayesian model combination, etc.
Bagging
Bagging is a technique that allows sampling of data in a way that the problem of overfitting can be dealt with. There is a variety of Bagging like Bagging, Pasting, Bootstrapping random Subspaces, as well as Random Patches. But, the method of Bootstrapping is commonly referred to as the method used to create Bagging. In this, various subsets of data from that training data set are selected randomly with the replacement. This helps in creating a group model, where the outcomes of these models are combined to produce one outcome. The most commonly used algorithm for bagging is the decision tree. Another popular variation of Bagging can be described as Random Forest, a combination of bootstrapping and Random subspaces in which the decision trees algorithm is utilized. The topic of this article is the concept of bagging, and the many aspects associated with it are discussed.
Boosting
It is a variation of bagging in only the previous model’s results that influence the following model’s output. This is where the process is taught by a series of. There are many kinds of Boosting, including Adaptive Boosting, Gradient Boosting, and Extra Gradient Boosting. Adaptive Boosting uses a range of weak learners whose process is taught sequentially through assigning weights to the mistakes. Gradient Boosting can be a variation of Adaptive Boosting, where Gradient Descent is utilized in conjunction with Adaptive Boosting. The Extra Gradient can be described as a refined version of Gradient Boosting along with all kinds of Boosting methods covered on this site.
Stacking
If a variety of models have been applied to data simultaneously, then this technique of modeling meta-ensemble can be referred to as Stacking. There isn’t a single function, but we have a meta-level in which the function is utilized to blend the outputs from diverse functions. This means that the data from different models are merged to create an original model. This is the most sophisticated form of data modeling commonly used in hackathons for data and other online competitions where the highest level of accuracy is needed. Stacking models may have multiple levels and be made extremely complex through various combinations of algorithms and features. There are various forms of Stacking methods which is why in the present blog article, a method of stacking called blending was investigated.