
Feature Scaling is one of the most vital steps of feature engineering as well as data pre-processing in general. To comprehend feature scaling clearly, we can look at an instance of a data set with two variables: income and average duration of Call. In order to evaluate them, we need them to be in the same range because income, for instance, is expressed in dollars, and the duration of calls is in minutes. To evaluate these factors, they have to be the same size, which is why feature scaling is helpful. Thus when some specific attributes have a higher ‘magnitude’ than others, due to values being in different units of measurement, it needs to scale all such attributes to bring them to comparable/equivalent ranges.
Use of Feature Scaling
Before examining the different ways that features can be scaled, it’s crucial to comprehend the significance of feature scaling as well as the implications of features that are not scaled. Many machine learning algorithms require feature scaling because it prevents the model from giving higher weightage to particular attributes compared to other attributes such as features.
Models for classification like KNN need features to be scaled when classifiers like KNN employ Euclidean distance to determine what distance two places are. And when one feature is located and separated into different units of measurement that cause it to be in many different values, it may affect the calculation and result in inaccurate and inaccurate results. This is why the change in measured space, i.e., it will be the Euclidean distance of two specimens, will differ after the transformation.
Gradient descent, which can be described as an algorithm for optimizing that is commonly employed to optimize the performance of Logistic Regression, SVM, Neural Networks, etc., is an additional example when features are on different scales, and some are updated more quickly than other weights. However, feature scales aid in creating Gradient Descent to reach a converge quicker as it puts all variables on an equal scale. For instance, linear regression. This allows for a simple calculation of how steep ( that is, y = MX + C) (where you normalize M’s parameter in order to speed up the process of converging).
Techniques for Feature Extraction like Principal Component Analysis (PCA), Kernel Principal Component Analysis (Kernel PCA), and Linear discriminant analysis (LDA) in which we need to determine directions by maximizing the variance. By scaling the features, we can be sure that we are not prioritizing variables with huge dimensions. For example, suppose you have one element (e.g., working hours per day) which has less variation than the other (e.g., monthly income) because of their scales (hours as opposed to. dollars). In that case, the direction of the maximum variance is closer to the axis of income, which PCA might determine. If the features aren’t scaled, an increase in one dollar’s income is considered much more significant than an increase over the course of one hour. In general, the only class of algorithms considered to be scale-invariant is the tree-based method, in contrast to the other algorithms like the Neural Network tends to become convergent faster. K-Means usually provide better clustering results, and different feature extraction methods provide better results with scaled features that have been pre-processed.
Techniques of Feature Scaling
There are a variety of ways in that features can be scaled, with each method having its unique strength and utility. The different scaling methods are described below.
Min-Max Scaling (Rescaling or Normalization)
The most straightforward way to scale that involves scaling the values within the range between the 0 and 1 range or from 1- 1 is Min-Max Scaling. The formula to scale values to encompass the range between 1 and 0 is
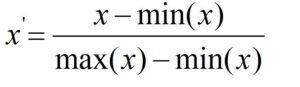
The formula to scale the values so that they range between 1 and -1 (making zero the central) is
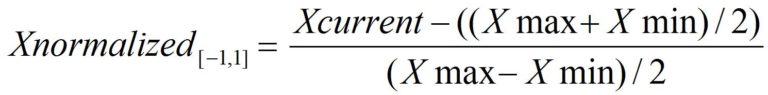
The most well-known option in Standardization (mentioned in the following paragraphs) aids in reducing the impact of outliers because it has smaller standard deviations from the output.
This technique is employed in algorithms like the k-nearest neighbor, where distances and regression coefficients need to be calculated. When the operation of the model is dependent on the size of values, the normalization process is usually used. In all the above scenarios it is standardization (mentioned in the next section) is the most commonly employed method. There are certain instances in which min-max scaling can be superior to standardization, for instance, in models in which image processing is needed. For instance, in different classification models where images are classified according to the intensity of the pixels, which vary between 0 and 254 (for RGB color range, i.e., for images with colored hues), Rescaling demands that the values are normalized only within this range. A variety of Neural Network algorithms also require features’ values to be in the range of 0-1, and Min-Max scaling can be useful for this purpose.
Z score Normalization (Standardization)
Z score normalization is simply changing the scale of the feature, so they have an average of zero and one standard deviation. The concept was discussed within Inferential Statistics; thus, the feature(s) will possess normal distribution properties.
the formula for calculating z-score
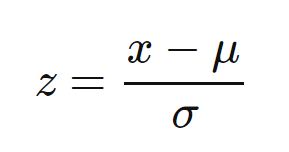
Standardization is among the most widely-used and utilized methods of rescaling. It is utilized in models that utilize machine learning algorithms like logistic regression, neural networks, etc. K-means algorithm and other clustering algorithms gain from standardization, specifically when Euclidean distances are to be calculated. Models that depend upon the spread of feature features, such as Gaussian methods, also need the standardization of the features. Many feature extraction techniques require the features to be scaled. Standardization is the most frequently used method, as Min-Max Scaling offers lower standard deviations.
In contrast, when employing feature extraction techniques like Principal Component Analysis, we must focus on the parts which maximize the variance. The process of feature Scaling is among the most essential aspects of data processing and, if needed, should be carried out before applying any type of Machine Learning algorithm. There are two main methods: Standardization and Normalization to scale the features, each with distinct advantages and disadvantages. Both can be applied based on the algorithm employed in the model.
If the features aren’t scaled, an increase in one dollar’s income is considered much more significant than an increase over the course of one hour. In general, the only class of algorithms that are considered to be scale-invariant is the tree-based method, in contrast to the other algorithms like the Neural Network tends to become convergent faster. K-Means usually provide better clustering results, and different feature extraction methods provide better results with scaled features that have been pre-processed.